Data Mining af strukturnøgletal
Chr. Kaasen, forår
2002
Strukturnøgletal
– et eksempel
Infouddragning – de individuelle nøgletal
Infouddragning – kombination af nøgletal
Infouddragning – sammenvejning af nøgletal
Bilag A – klassificering af virksomherne
Bilag B – gennesnitsværdier alle
observationer
Bilag C – rangordnede gennemsnit pr.
virksomhedstype
Bilag D – normaliserede afstande mellem
virksomhedstyperne
Som begreb er data mining (DM) af forholdsvis
ny dato. De største og mest citerede værker er alle skrevet indenfor de seneste
5 år og DMprogrammer som SPSS´ s
Clementine og SAS´s Enterprise Miner har kun nogle få år på bagen[1].
På trods heraf - eller måske netop derfor - ses referencer til DM i mange og
vidt forskellige sammenhænge - ofte nærmest som en slags ”Sesam luk dig op”
-trylleformular, der er i stand til åbne døren til en skjult informationsskat
eller for at blive i den faglige jargon finde ”guldklumper” i en enorm og
uoverskuelig informationsmængde. Det åbne spørgsmål er naturligvis: er der ægte
guldklumper[2] i
virksomhedens data eller er det bare glimmer? Det forhold at store, erfarne og
agtværdige statistikprogramhuse har udviklet og inkluderet særskilte produkter
med denne etikette i sortimentet lader formode, at de i det mindste anser det
for en kommerciel salgbar artikel. Men hvordan ser det ud fra et
brugersynspunkt? Er der tale om ny etikette på gamle flasker eller er der tale
om en ny fagdisciplin afledt af den informationsteknologiske udvikling og med
blivende værdi?
I dette notat redegøres først for nogle hovedtræk i
begrebet DM og derefter vises et mindre eksempel på hvordan en manuelt udført
DM-lignende analyse kan gennemføres.
Data mining
Lidt løst udtrykt kan man sige, at filosofien bag DM
er at skabe ny viden ved at ”presse” upåagtet information ud af de enorme
mængde rådata, som de moderne EDB-baserede registreringer har skabt. Tanken er
her, at de store systematiske datamængder - eksempelvis kassebonnerne i et supermarked
- indeholder skjult information, som gennem en – ofte meget omfattende – DM kan
gøres til brugbar viden. Afslører en DM af kassebonner – benævnt ’basket analysis’ - f.eks. at nogle
varer, som ikke har en brugsmæssig sammenhæng, alligevel meget ofte købes
samtidig, kan denne information gøres brugbar dels gennem varernes placering i
forretningen (skal de stå ved siden af hinanden eller i hver sin ende af
forretningen?) og i tilrettelægningen af den ugentige tilbudsavis, hvor man så
på skift kan have de købssammenhørende varer på tilbud.
Sigte
og mål
I et af hovedværkerne om DM - ”Data Minining
Techniques” - fra 1997 angiver forfatterne Berry og Linoff følgende definition
på DM:
”Data mining ......... is the exploration and analysis, by automatic or semiautomatic means,
of large quantities of data in order to discover meaningful patterns and rules” (Berry og Linoff, 1997, s.5)
og side 18 angives formålet med denne analyse:
” .......merely finding the patterns is not enough. You must be able to respond to the patterns, to act on them, ultimately turning the data into information, the information into action, and the action into value” (op. cit. p. 18)
SAS´s definition af DM er lidt mere kommerciel:
”Data
mining is the process of selecting, exploring and modelling large amounts of
data to uncover previously unknown patterns for business advantage” (http://sas.com/technologies/data_mining)
Det centrale er altså om analysen skaber brugbar
viden – det vil sige om analysens resultater skaber grundlag for mere
profitable handlinger. SAS´s lidt mere dæmpede målkrav til analysen svarer mere
til de forfattere, der tilkendegiver, at et bedre resultat / større forventede
værdi er at foretrække, men at en reduktion af usikkerheden også er en
værdifuld fordel – f.eks. ved at undgå besværlige / tidrøvende / tabsgivende
kunder eller ved at accellerere beslutningsprocessen. DM er altså et
besluningsstøtteværktøj på linie med statistik, køteori og operationanalyse.
Der er dog en markant forskel: førstnævnte er i al væsentlighed induktiv medens
de 3 sidstnævnte er af deduktiv karakter.
Eksempel: En
kontokortudsteder ønsker at bestemme hvilke faktorer der er årsag til misligholdelse.
I en traditionel statistisk analyse vil første skridt være at opstille en
hypotese eksempelvis at indkomsten er afgørende. Hvis dataene ikke kan
verificere indkomstens betydning opstilles en ny hypotese eksempelvis at
kontokortholderens gæld er afgørende for misligholdelsen. Kan dataene heller
ikke understøtte denne hypotese, ville indkomst i forhold til gæld være en 3.
hypotese, der kunne testes. Ved en traditionel statistisk analyse genereres
således en række hypoteser, som én efter én testes på dataene – altså en
deduktiv fremgangsmåde. Ved store datamængder bliver denne fremgangsmåde
hurtigt helt uoverskuelig. DM-teknikkerne er derimod indrettet på at kunne
håndtere store datamængder. I stedet for at bekræfte hypoteser anvendes dataene
til at afdække mønstre og / eller sammenhænge. I nærværende eksempel ville en
DM-analyse helt ukritisk anvende alle tilgængelige informationer og kunne
eksempelvis fremkomme med et resultat at alder, postnummer, indkomst og gæld –
evt. i vægtet format – bedre end noget andet kan identificere potentielle
misligholdere. Den deduktive fremgangsmåde vil sædvanligvis være styret af en
årsag - virkning sammenhæng, medens de induktive DM-metoder ikke er begrænset
af sådanne betragtninger og derfor også kan fremkomme med overraskende og
uventede resultater – dvs. sammenhænge som hverken teoretisk eller logisk kan
forklares, men som dog ses i eller fremgår af dataene
Som udgangspunkt er DM en ”bottom up” strategi. Det
vil sige at DM er data drevet i modsætning til sædvanlige statistiske
undersøgelser - der med nævnte terminologi er en ”top down”-strategi - idet
sådanne er brugerstyret dels i form af brugerdefinerede kriterier, dels
i form af en af brugeren formuleret hypotese. Her er dataenes funktion
begrænset til ’kun’ at verificere eller
falsificere hypotesen iht. til de opstillede kriterier. DM er ”tallenes tale”
til brugeren og deres tale er mængder – nemlig overnormale hyppighheder eller
koncentratrioner af visse data eller data-kombinationer, der kan omsættes i ny
viden og dermed forbedre beslutningsgrundlaget.
Datastyringen implicerer at der anvendes mere eller mindre automatiserede metoder, som efter nogle gennemløb af dataene kan frembringe en model. Typisk udvikles modellen på en delmængde af dataene for derefter at blive testet på en anden delmængde. Testen medfører ofte en yderligere præcisering af modellen, som derefter skal testes på en tredie delmængde af dataene o.s.f. En sådan ’træning’ af modellen kan naturligvis nemt resultere i ’overfitting’ hvorved forstås en næsten 100% korrekt gengivelse af de historiske træningsdata. I sig selv er der intet negativt i at modellen trænes til høj grad af perfektionisme på et givet datasæt. Det bliver først problematisk når overfittingen skaber forventninger om at modellen vil have samme udsagnskraft i fremtiden på helt andre data. Det vil den ikke – ofte bliver dens forudsigerkraft næsten halveret på fremtidige data.
Afdækningen af meningsfyldte mønstre og
regelmæssigheder kræver omfattende og systematiske registreringer både mht.
antal poster og mht. antal variable.[3] Lidt firkantet sagt er antallet af poster
afgørende for, hvor sikkert en model kan fastlægges, medens antallet af
variable er afgørende for hvor mange modeller, der kan undersøges. I DM er
dataenes funktion derfor både modelkonstruk-tion og modelvalidering – altså en
langt mere omfattende opgave end i traditionelle statistiske
undersøgelser. Fokus er således flyttet
fra at finde den rigtige model – og dermed også den bagvedliggende
forklaring – til at finde de rigtige informationer – dvs de mest
anvendelige informationer. Der er således ingen nævneværdig forudgående
teoretisk begrundet udvælgelse af variable og sammenhænge ligesom de fra
hypoteseprøvningen kendte 5 og 1% signifikansværdier er mindre væsentlige i DM.
Der er dog ikke tale om en enten eller situation, men snarere både og, idet
DM-analysens resultater ofte vil blive verificeret og evalueret med
traditionelle statistiske metoder, der er langt bedre til at angive
sammenhængenes styrke i en kendt og anerkendt form.
I forhold til traditionel statistisk hypoteseprøvning er det således en meget prunkløs og pragmatisk modelevaluering i DM. Det gør naturligvis ikke DM mindre seriøs, at teoretikernes ofte noget abstrakte termer er erstattet af et meget mere håndgribeligt ’værdiskabelseskriterium’. Et sådant kriterium er i langt bedre overensstemmelse med virksomhedsledelsens dagligdag og begrebsverden, hvor lakmusprøven for beslutningernes kvalitet netop er deres positive effekt, og vil alene af den grund være mere handlingsskabende. Teoretikernes krav om 95 % eller 99 % sikkerhed vil i sig selv ofte virke handlingslammende i en beslutningssituation, idet det vil være uhyre sjældent, at der kan opnås så overbevisende sikkerhedsmarginer i erhvervslivet. En reduktion af de teoretiske sikkerhedskrav eller konfidensintervaller vil derfor også øge DM´s operationalitet.
DM tilgodeser først og fremmest brugerens behov for
handleinformation fremfor teoretikerens behov for overbevisende
hypotese-falsifikation. Selvom den statistiske forklaringskraft kan beregnes
til at være ret ringe, vil det dog ofte være således at udsagnskraften er
tilstrækkelig til at være interessant i en forretningsmæssig sammenhæng. For en
beslutningstager vil en statistisk signifikans på 95 ud af 100 være ganske
uinteressant hvis hans normale succésrate ligger på 2 ud af 3. Alt hvad han
ønsker er at den fremtidige succésrate forøges udover dette niveau. I DM bliver
den logiske og metodemæssige modelevaluering derfor stort set lig med en
pragmatisk modelverifikation – helst i form af en nøje overvåget og ofte klart
af- og begrænset eksperiment, som kan bekræfte / afkræfte, at dens udsagnskraft
giver et bedre resultat – ’the proof of the pudding is in the eating’ –
alternativt kan en testdatabase anvendes.
Metoder
DM gør brug af et stort antal meget forskellige
metoder. Da hyppigheder,
koncentrationer, samvariationer, associationer og kategoriseringer hører til
blandt de hyppigste mål for analyserne, er de statistiske metoder naturligvis i
overtal, men der er tilsyneladende også hentet inspiration fra køteorien og
operationsanalysen. Der er dog ofte tale om en betydelig udbygning af de
klassiske statistiske metoder. Udviklingen af de klassiske statistiske
teknikker har sædvanligvis været baseret på anerkendte teoretiske og metodiske
overvejelser og for en overskuelig og til den givne teknik tilpasset
datamængde, eksempelvis mht. fordelingens art
– mao. teknikkernes anvendelse hviler på en række forudsætninger af
såvel teoretisk som datamæssig karakter. Dette er ikke tilfældet for
DM-teknikkerne. De store metode-utilpassede datamængder har nødvendiggjort og
adgangen til stadig større og mere kraftfulde computere har muliggjort en
udvikling af teknikker og metoder baseret på rå og brutal regnekraft – altså en
helt anderledes kraftbetonet tilgang til analysen .
En gruppering af de mange metoder kan gøres ud fra
karakteren af det output de enkelte metoder frembringer. Svarende til en
statisk / dynamisk synsvinkel kan DM-metoderne hensigtsmæssig opdeles i
metoder, der sigter mod at beskrive og i metoder, der sigter mod at forudsige[4].
I litteraturen fremhæves at en DM-analyse altid bør
starte med en meget tæt og præcis beskrivelse af de data som skal indgå i undersøgelsen
herunder en bestemmelse af datatype – kontinuerte eller kategoriale variable
(sidstnævnte kan yderligere splittes i ordinale (høj, mellem, lav) eller
nominelle (postnumre) variable). Udover
beregning af gennemsnit, standardafvigelse, standardise-rede 3. og 4. momenter
anbefales bred anvendelse af grafiske afbildninger som f.eks.
frekvensfordelinger, histogrammer samt 2- eller 3-dimesionelle afbildninger
evt. vha. af pivottabeller. Sidstnævnte kan også være brugbare til
homogenitetstests.
Klyngeanalyse (clustering) henregnes til
databeskrivelsesteknikkerne. Sigtet hermed er at inddele datamaterialet i
grupper / klynger hvor enhederne indenfor grupperne har en betydelig lighed og
hvor enhederne mellem grupperne adskiller sig mest mulig. Klyngeanalysen
adskiller sig fra klassifikation ved at man på forhånd ikke kan vide hvilke
egenskaber eller egenskabskombinationer, der danner grundlag for
klyngedannelsen medens klassifikation / segmentering altid sker ud fra kendte
baggrundsvariables værdier. Klyngedannelse kan udføres ved hjælp af forskellige
teknikker, hvor de underliggende algoritmer som oftest dog er baseret på
varians / kovariansmatricen. Ekstrahering af en fælles faktor, der knytter alle
enheder sammen i de enkelte klynger, er en overordentlig vanskelig opgave, som
stort set er overladt til den menneskelige hjerne og fantasi. Den bedst kendte
og mest veludviklede teknik er utvivlsomt faktor-analysen, som uanset dens
eksplorative karakter normalt henregnes til den klassiske statistiks metoder og
af samme grund ikke ses i de kommercielle DM-programmer. Eksempelvis er denne metode meget anvendt
inden for markedsundersøgelser til at finde frem til forskellige forbrugeres
livsstilsmønstre og netop problemet med at finde en fælles dækkende etikette
for de enkelte klynger har bevirket en helt intetsigende navngivning efter
farver – blå, grøn, violet, rosa og grå!
Nogle forfattere har dog forsøgt at identificere en fælles
karakteristisk faktor for de enkelte klynger som ’konservative kvalitets-forbrugere’,
’trendy forbrugere’ mv.
Til beskrivelsesteknikkerne henregnes også
kædeanalyse (link analysis), hvis sigte er at identificere sammenhænge –
associationer – i datamaterialet. I sin grundform er det en langt enklere
teknik end eksempelvis klyngeanalysen, idet samhørigheden bestemmes ved
optælling af sammenfald og beregning af relative og betingede hyppigheder.
Bonanalyse er en typisk kædeanalyse, hvor det undersøges hvor hyppigt
forskellige varer købes samtidig – aktivitetsbetinget samhørighed – medens
sekvensbetinget samhørighed beregner hyppigheden af sammenfald over tiden.
Metoder til forudsigelser underopdeles sædvanligvis
efter outputtets form: 1)
klassifikationsmetoder – kategorialt output, 2) regressionsmetoder – kontinuert
output og 3) tidsseriermetoder – mønster output. Metoderne i denne gruppe skal
trænes – dvs. de skal udvikles og testes på baggrund af et historisk materiale
hvor såvel inputvariablernes som resultatvariablernes værdier er kendte.
Klassifikationsmetoderne sigter mod at identificere
de karakteristika, der bedst mulig angiver hvilken klasse den enkelte
observation tilhører. I den mest simple form er det en opdeling i at være
eller ikke at være – at være en sandsynlig kunde eller at være en ikke
sandsynlig kunde, at være misligholder af et lån eller ikke misligholder
osv. Den ideologiske basis for
klassifikationsmetoderne kan henføres til
R. A Fishers diskriminantanalyse fra 1935, men teknisk set er der sket en betydelig udvikling af metoden.
Moderne diskriminantmetoder kan inddele et observationsmateriale i mange
klasser og kan håndtere mange forskellige former for afhængighed mellem de
indgående variable.
Beslutningstræet henregnes sædvanligvis også til
klassifikationsmetoderne. Det er en central metode i alle DM-programmer og den
ses i mange varianter. Metodens popularitet skyldes dels at den logiske
opdeling gør den umiddelbart forståelig og ofte også at forgreningerne direkte
kan omsættes til handlinger som kundegruppering, sortimentsammensætning
o.lign., dels at computeren er ideel til at sortere og lave betingede
udvælgelse i et stort datamateriale. Desuden kan beslutningstræet uden
problemer tage hånd om kategoriale som kontinuerte variable – hver for sig
såvel som blandet. En selectering efter bopæl og købsfrekvens (kategoriale
variable) sammen købstørrelse (kontinuert variabel) kan nemt formuleres som en
SQL-statement. Der findes dog også en række mere datastyrede algoritmer til
udvælgelse af de bedste opdelinger, der bl.a. sikrer at variationen indenfor
gruppen minimeres medens variationen mellem grupperne / grenene maksimeres som
f.eks. CHAID (Chi-squared Automatic Interaction Detection) og CART
(Classification And Regression Trees). Især ved kontinuerte variable bør de datastyrede
algoritmer anvendes, idet en traditionel opdeling i afrundede klumper på ingen
måder sikrer gode afskæringsværdier – eksempelvis kunne en sådan være
indkomsten, der ofte inddeles i intervaller som 300.000 kr til 500.000 kr, men
er en indtægt på 500.001 kr så meget bedre, at den ikke hører med til
intervallet?
Kunstig neurale netværk er som regel flagskibet i de
fleste DM-programmers regressionsmodeller.
Neurale netværk kræver at inputvariablerne er
kontinuerte. Et sådant netværk består
principielt af 3 lag noder: inputnoder, skjulte indre noder (med et billede fra
hjerneforskningen betegnes de ofte som neuroner, hvilket dog forekommer at være
en alt for positiv allegori) og outputnode(r). Hver inputnode er forbundet med
alle indre noder og alle indre er forbundet med outputnode(rne) . De skjulte
noder indeholder en aktiverings / frembringerfunktion, som hver især aktiverer
en vægt, som indgår i beregningen af outputtet. En sådan model skal trænes
rigtig meget, hvilket gøres ved at fodre den et sæt sammenhørende værdier af
inputvariablerne og outputvariablerne. Ved hver fodring indstiller de indre
noders funktioner sig på en værdi, som sikrer, at det ønskede output nås. De
indre noder husker disse værdier og ved næste fodring anvendes de til at frembringe
/ beregne et output. Afviger dette beregnede output fra det aktuelle kendte
output svarende til de givne input-værdier, indeholder netværket mekanismer til
at korrigere vægtene, således at det beregnede resultat svarer til det
realiserede resultat. Også disse nye / korrigerede vægte huskes til næste
beregning. Ved hvert gennemløb bliver netværket ”klogere” dvs. at de aktive
noder finjusterer vægtberegningerne og/eller flere noder aktiveres for at kunne
frembringe det ønskede resultat.
Efter forbillede fra den menneskelige hjerne med dens
mange neuroner, der enten er aktive dvs. afgive en impuls eller ikke aktive,
var de indre noders aktiveringsfunktion en diskret funktion, der kunne antage
værdien 0 eller 1. Matematisk set er det en ret besværlig funktion og derfor
anvendes som regel sigmoid-kurve – dvs en S-formet kurve (altså en logistisk
funktion) i intervallet 0 til 1, dvs stort negativt input og stort positivt
input vil have værdier på hhv. 0 og 1. I et snævert interval omkring 0 skifter
funktionen. Når modellen trænes ’lærer’ de for hvilke inputværdier de skal være
aktive – altså afgive en impuls til (”tænde for”) vægtberegningen af outputtet.
Antallet af noder og / eller antal aktive noder og hvilke tærskelværdier der
har aktiveret dem er det sædvanligvis ikke muligt at få oplyst. I store netværk
kan der være flere lag skjulte indre noder, hvor første lags beregnede vægte
bruges som inputværdier i andet lags noder hvorefter de beregnede vægte herfra
enten anvendes i et 3. lag eller anvendes til at beregne outputtet. Men uanset
om der er 1 eller flere skjulte lag noder vil outputtet være en ikke-lineær
kombination af inputnoderne. Helt specielt gælder dog, at hvis outputnoden
indeholder en lineær aktiveringsfunktion og at der ikke findes skjulte noder så
vil det neurale netværk være en multipel lineær regression med samme antal
variable, som der er inputnoder.
Et neuralt netværk fungerer altså som en ”black box”,
der på én eller anden ukendt måde transformerer et input til et output, hvilket
bevirker, at det stort set er umuligt at fortolke reultatet - herunder at give et mål for usikkerheden i
resultatet, at beregne følsomheden over for variationer i inputværdierne,
angive modellens robusthed o.lign. Billedligt talt er et neuralt netværk en
”målet helliger midlet maskine”, idet anvendelsen af et sådant netværk helt
klart er udtryk for at resultatet prioriteres betydeligt højere end
forklaringen. Denne totale negligering af årsag-virkning sammenhængen er udtryk
for ren pragmatisme, der for en bruger / beslutningstager kan virke
tiltrækkende, men den, der er afhængig
af resultatet, kan meget vel have en helt anden opfattelse. En student, der
søger optagelse på universitetet og får afslag med begrundelsen ”Vort neurale
netværk siger ’dur ikke’ ” vil næppe finde et sådant orakelsvar passende
uanset om afvisningen er baseret på hele universitets erfaringsmasse omkring
studiegennemførelse. En vis
forsigtighed i omgangen med neurale netværk synes påkrævet.
Alle former for regression – lineær, multipel,
kvadratisk, logistisk osv. – er også standardværktøjer i DM-pogrammerne. Da
disse modeller hviler på et kendt og teoretisk anerkendt metodegrunglag er
tolkningsmulighederne langt bedre og sikrere end i et neuralt netværk. Dog kan
selv disse metoder give visse forklaringsproblemer. Inkorporering af et
interaktivt led i en multipel lineær regression fordi det forbedrer
korrelationskoefficienten og dermed
giver et mere præcist output er i sig selv ikke nogen forklaring på
hvorfor og hvordan de 2 inputvariable interagerer. Kan en sådan interaktion
mellem 2 inputvariable ikke logisk begrundes, er der tale om et relativt fald i
forklaringsevnen og dermed tilliden til modellen selvom dens forudsigelser
forbedres ved medtagelse af det interaktive led. De seneste årtiers enorme
erfaringshøst med regressinsmodeller har dog givet en voksende erkendelse af
deres robusthed overfor mangler og brister i de teoretiske og datamæssige
forudsætninger for deres anvendelse og dermed også en vis berettiget
tilbøjelighed til helt eller delvist at se bort fra en sådan logisk evaluering
af modellen. For blot 25 år siden
betragtedes eksempelvis dummyvariable med en betydelig skepsis – de er ikke
normalfordelte; i dag indgår de uden
advarende ord i enhver statistiklærebog.
Tidsseriemetoderne kan være såvel matematik som
computerbaseret. Medens de matematiske modeller som hovedregel er tidsstyrede –
dvs. afhængig af at begivenhederne finder sted på samme tidspunkt eller med
konstante tidsmellemrum – er de computerbaserede metoder som regel
begivenhedsstyrede. Computeren har en uovertruffen evne til at kunne fastholde
en sekvens af begivenheder og ved ren og skær sammenligning at kunne
identificere alle lignende sekvenser – også selvom tiden mellem begivenhederne
varierer.
Ovennævnte hurtige og overfladiske kig i DM´s ganske
omfangsrige værktøjskasse er på ingen måder udtømmende hverken mht. antal metoder, deres formåen
eller deres anvendelighed. De kommercielle DMprogrammer vil ofte også indeholde
analysemetoder, som programhusene selv har udviklet - såkaldte proprietærmetoder – samt en procesmodel, der i en
række faser angiver hvilke opgaver, der skal løses for at nå et godt resultat.
En række europæiske selskaber med deltagelse af bl.a. NCR Denmark har udviklet
en sådan procesmodel kaldet CRISP-DM – Cross-Industry Standard Proces for Data Mining.
Udover den omfangsrige metodeværktøjskasse er det
også kendetegnende, at i DM anvendes metoderne ofte i lag. Resultaterne fra én metode anvendes ofte som
input i en anden metode og resultaterne herfra kan så eventuelt anvendes i en
3. metode. Baggrunden herfor er bl.a. den, at dataene ikke er indsamlet med en
speciel eller veldefineret analyse for øje i modsætning til den traditionelle
statiske analyse, hvor mønstret kort kan gengives som: hypoteseformulering,
undersøgelsesdesign, operationalisering, dataindsamling, hypotesetest og
konklusion. I den datadrevne DM vil de tre første faser ofte blive gennemført
vha. af nogle standardiserede metoder og resultaterne herfra indgår derefter som
inputvariable i andre metoder. Da målet med DM er maximal handleinformation,
vil en flertrinsanalyse ofte også give et mere komplet billede af
virkeligheden,
så også af den grund vil metoderne ofte anvendes i
lag.
DM kan anvendes i alle tilfælde hvor datamængden er
tilstrækkelig omfangsrig og systematisk til at den understøtter
modelkonstruktion og modeltest. De største datamængder fremkommer som regel i
forbindelser med transaktioner og det er da også netop kunderelationer og
kundeadfærd, der hyppigst fremdrages som eksempler i litteraturen.
Kundeloyalitet er et af de centrale genstandsfelter for DM-undersøgelser. Ud
fra en umiddelbar betragtning vil en sådan undersøgelse stille krav om at
kunderne kan identificeres som individuelle kunder, hvilket bl.a. er tilfældet
for banker, forsikringsselskaber, telefonselskaber, rejsebureauer,
postordrefirmaer, apoteker m.fl. Ved transaktioner, der er baseret på
kontantbetaling, er det derimod ikke så lige til at identificere den enkelte
kunde. Dog i de tilfælde, hvor betalingen overvejende sker ved hjælp af kredit-
eller betalingskort kan kan kortets kode identificere de enkelte salg omend
kunden som sådan er ukendt. Ubemandede benzinstationer er et godt eksempel på
en sådan virksomhed. Klikanalyse dvs. sporingen af internet-kunders vej frem
til køb eller det modsatte er ligeledes et stort emne for DM – en analyseform
Jubii bl.a. har udnyttet til at prissætte visse af portalens ydelser.
Udpegning af dubiøse debitorer, lager-, sortiments-
og logistikanalyser er eksempler på en virksomhedsintern anvendelse. Et tredie
område er overvågning og sporing af kriminelle handlinger. PBS bruger således
datamining til at overvåge brugen af dankort bl.a. med henblik på sporing af
ulovlig anvendelse af kortet, medens visse forsikringsselskaber leder efter
mulig forsikringssvindel. På børserne er det insiderhandel, der er genstand for
overvågning.
Normalt vil selskabets egen database danne baggrund
for en DM-undersøgelse, men ofte vil den blive suppleret med data fra
offentlige statistikker eller speciel indsamlede data. Trafikintensiteten og
konkurrenternes beliggenhed kunne eksempelvis give andre dimensioner i et
benzinselskabs analyser af
kundeloyaliteten.
Evaluering
Det afgørende nye i DM er først og fremmest
omkostningseffektiviteten. Tidligere var omkostningerne ved statistisk
vidensproduktion nærmest prohibitive: lang tids forberedelse med planlægning og
design ofte med hjælp af dyre eksperter, omhyggelig og dermed dyr
dataindsamling, som regel meget enstrengede og tidkrævende dataanalyse på ikke
altid lige velegnede main frames og med betydelig usikkerhed om brugbarheden af
de frembragte resultater var forhold, som i de fleste tilfælde gjorde en sådan
vidensproduktion aldeles uinteressant for det store flertal af virksomheder.
Den omfattende og stærk stigende elektroniske
registrering har sammen med et enormt prisfald på harddiske givet en
datatilgængelighed, der er forbedret mange mange gange i de seneste 25 år og
til omkostninger, der med datidens øjne nærmest kan betragtes som gratis. Data,
der er indsamlet som et led i forretningsmæssige transaktioner, vil naturligvis
ikke altid være lige velegnede til en DM, og ofte må der da også udføres en
såkaldt datarensningsproces – data cleansing – der gør dataene brugbare. Da
datarensningen i vid udstrækning kan gøres elektronisk vil det dog ikke medføre
nævneværdigt større omkostninger ved datatilgængeligheden.
Omkostningerne ved selve databehandlingen er ligeledes
decimeret mange gange. Fordoblingen af processorerne hastighed hvert andet år
samtidig med at båndbredden er 4-5doblet og prisen på 1 MB RAM er faldet til
brøkdele af datidens priser har medført en enorm stigning i
behandlingskapaciteten til stadig stærkt faldende omkostninger. Muligheden af at kunne parallelforbinde
PC´ere i et netværk har ligeledes mangedoblet databehandlingskapaciteten.
Medens udviklingen på hardwaresiden er særdeles
synlig og spektakulær er dette ikke helt tilfældet mht. softwaren. Det forhold
at store stærke og velgennemtestede statistikpogrammer er gjort umiddelbart
tilgængelige for afvikling på billige PC´ere har utvivlsomt skabt en bedre og
bredere metodefortrolighed og dermed banet vejen for DM´s udbredelse. Hertil
kommer meget store forbedringer i brugervenligheden både hvad angår
operationalitet og resultatpræsentationen. GUI og SQL er selvfølgeligheder i
den forbindelse hvorimod modelbygning med grafiske pictogramlignende objekter
er af helt ny dato. Hvert pictogram dækker over en standardiseret algoritme der
på forskellige måder kan føjes sammen til en komplet fuld funktionel model
næsten som legoklodser, der kan anvendes til at bygge huse såvel som tog og
rumstationer. En sådan visualisering
skaber oveblik, synliggør sammenhænge og skaber fokus. Grafisk repræsentation
af af inputdata og resultatvariable -
såvel todimensionalt som tredimensionalt
- er ligeledes udtryk for en forbedret brugervenlighed.
Historisk set er mange af metoderne udviklet indenfor
de seneste par tiår af uafhængige forskere – ofte med henblik på løsning af
specielle problemstillinger og ikke som et egentlig DM-værktøj. Et fælles
kendetegn for disse metoder er deres eksplorative karakter og væsentligst på
dette grundlag er de fagdisciplineret under et noget misvisende, men
kommercielt set meget fordelagtige begreb: Data Mining. Som det normalt er
tilfældet har denne afgrænsning utvivlsomt været en fordel: øget faglig og
teoretisk interesse, afdækning af huller og mangler, mere konsistent begrebsdannelse,
øget metodeformalisering anføres sædvanligvis som de væsentligste. Men også
kommercialiseringen har sine fordele: øget tilgængelighed, større
brugervenlighed, udvikling af effektive og robuste algoritmer og ikke mindst en
økonomisk sikkerhed for fortsat interesse. Kommercialiseringen har dog også
sine negative sider. Anvendelsen af ikke-standardiserede, fancy, men
storsælgende betegnelser – tilsyneladende helst i form af akronymer – gør
materien mere vanskelig tilgængelig end nødvendigt.
Implementering af DM er en omfattende og tidkrævende
aktivitet, men i modsætning til tidligere tiders statistiske undersøgelser, der
typisk var en enkeltstående affære, er DM beregnet til at indgå permanent i
styringsprocessen. Dette sammen med muligheden for omfattende flerstrengede
analyser af datamaterialet giver et
langt mere facetteret og tæt nutidsbillede af virkeligheden og dermed også
mange gange større sandsynlighed for at resultatet er brugbart – dvs
værdiskabende. De ofte relativt tynde sikkerhedsmarginaler stiller naturligvis
skrappe krav til overvågningen af modellernes troværdighed og effektivitet og
til en løbende opdatering.
Omkostningseffektiviteten er en nødvendig, men dog ikke tilstrækkelig forudsætning – den skal kombineres med et erkendt skifte i resultatevalueringen. Ændringen fra den videnskabelige forståelse og tolkning af et givet analyseresultat til en evaluering ud fra en økonomisk synsvinkel har bogstaveligt talt og i overført betydning rykket grænser. Akcepten af, at en merindtægt, der overstiger meromkostningen ved vidensproduktionen, er tilstrækkelig legitimering af en analyses resultatmæssige kvalitet, bevirker at mange flere analyser vil være handlingsskabende og dermed potentielt værdiskabende. Medens videnskaben vurderer resultatet ud fra idealet 100% korrekt er udgangspunktet for DM det aktuelle informationsniveau i virksomheden.
 Ud
fra traditionelle videnskabelige præmisser og kriterier kan DM i bedste fald
betegnes som pragmatisme og i værste fald som krystalkuglekigning. Meget
populært kan man sige at DM med den store vægt, der lægges på gennemsnit,
overrepræsentation, koncentration blot er en (videnskabelig?) metode til at
danne fordomme og tommelfingerregler for beslutningstagere, som ikke har fået
dem ind med mesterlæren. ’Leveregler’, ’måder’, ’ faglige normer’ o.lign., der
tidligere krævede generationers erfaringer for at kunne blive formuleret, kan
nu extraheres i brøkdele af et år.
Ud
fra traditionelle videnskabelige præmisser og kriterier kan DM i bedste fald
betegnes som pragmatisme og i værste fald som krystalkuglekigning. Meget
populært kan man sige at DM med den store vægt, der lægges på gennemsnit,
overrepræsentation, koncentration blot er en (videnskabelig?) metode til at
danne fordomme og tommelfingerregler for beslutningstagere, som ikke har fået
dem ind med mesterlæren. ’Leveregler’, ’måder’, ’ faglige normer’ o.lign., der
tidligere krævede generationers erfaringer for at kunne blive formuleret, kan
nu extraheres i brøkdele af et år.
Strukturnøgletal – et eksempel
Nærværende eksempel på en manuelt gennemført analyse baseret på et DM-lignende koncept er baseret på dagbladet Børsens Top500 oversigt over de 500 største virksomheder i Danmark. Udover navnet på virksomheden samt en branchekode indeholder oversigten tillige nogle få centrale regnskabsdata med omsætning, balance og antal ansatte som de mest interessante. Det centrale spørgsmål i nærværende sammenhæng er: Indeholder dataene brugbar information udover den umiddelbare der ligger i tallenes størrelse (og som af dagbladet Børsen bl.a er anvendt til at rangordne selskaberne efter – størst overskud, flest ansatte, største omsætningsstigning o.lign.) og i givet fald: er det muligt at tappe den – gøre den tilgængelig og brugbar? Dette er i al væsentlighed problemstillinger som DM forsøger at løse.
Flere steder i litteraturen diskuteres om miningen skal foregå direkte i databasen eller om der skal laves et i udtræk til en flad fil (regnearksfil). Ved virkelig store datamængder anses den direkte mining for eneste mulighed, mens andre fremhæver, at den flade fil giver mulighed for en tæt procesovervågning, som dels kan inspirere til yderligere analyser, dels målrette analysen mere effektivt end den rene datastyring kan. Analysen her er udført i Excel regneark og hovedsagelig under anvendelse af statiske metoder hentet fra ”Student CD” fra Bowerman, O’Connell og Hands ”Business Statistics in Practice”
I DM vil det ofte være således at man knap nok aner hvilken information man søger efter og da slet ikke hvilken form den optræder i. Selvom informationen ligger skjult i dataene vil søgningen efter den dog sædvanligvis ikke foregå helt i blinde. Tidligere erfaringer, tilfældige bemærkelsesværdige observationer, teoretiske overvejelser og lignende kan danne baggrund for en søgestrategi, der selvom den ikke er direkte målrettet, dog er metodisk og systematisk tilpasset situationen.
Udgangspunktet for nærværende analyse kan findes i stort set alle elementære økonomibøgers kapitel 1- ”En virksomhed” - omend de senere års markante pensumreduktioner stort set har fjernet enhver substans i emnet. I Waarst m.fl. ”Regnskabslære /Driftsøkonomi” fra 1988 er der givet en set med nutidige briller grundig og omfattende gennemgang af virksomhedsbegrebet herunder en opdeling af virksomhederne i forskellige typer og at denne opdeling bl.a. afspejler at de økonomiske forhold og at styringen er forskellig i de forskellige virksomhedstyper. Den traditionelle typologisering – industri opdelt i undergrupperne ordre-, serie- og procesproducerende, handel bestående af detail og engros samt servicevirksomheder – vil være et pejlemærke for nærværende DM.
 Hvis ovenstående præmis – at
virksomhedstype og økonomi er tæt forbundne – holder, må det også påvirke i det
mindste strukturnøgletallene. Af de 500 datasæt beregnedes derfor følgende
nøgletal: omsætning/balance, (aktivernes omsætningshastighed), omsætning/antal
medarbejdere (omsætning pr medarbejder)
og balancesum/antal medarbejdere (investering pr medarbejder) for hver
virksomhed. 27 datasæt var mangelfulde og blev smidt ud af analysen, medens virksomhederne
med de 40 mest ekstreme værdier blev holdt udenfor analysen. For god ordens
skyld nævnes, at der ikke er foretaget kontrol af eller rettelser i Børsens
data.
Hvis ovenstående præmis – at
virksomhedstype og økonomi er tæt forbundne – holder, må det også påvirke i det
mindste strukturnøgletallene. Af de 500 datasæt beregnedes derfor følgende
nøgletal: omsætning/balance, (aktivernes omsætningshastighed), omsætning/antal
medarbejdere (omsætning pr medarbejder)
og balancesum/antal medarbejdere (investering pr medarbejder) for hver
virksomhed. 27 datasæt var mangelfulde og blev smidt ud af analysen, medens virksomhederne
med de 40 mest ekstreme værdier blev holdt udenfor analysen. For god ordens
skyld nævnes, at der ikke er foretaget kontrol af eller rettelser i Børsens
data.
Børsen giver ingen forklaring på branchetilhørsforholdet, men et blik ned over de ialt 21 brancher (se tabel 1) lader formoder er der er tale om en skøn sammenblanding af juridiske, markeds-, funktions- og produktionsmæssige forhold. Beregning af gennemsnit og spredning af de 3 nøgletal for hver af de 21 brancher viser klart, at der ikke i de brancheopdelte nøgletal kan spores et branchetilhørsforhold. Gennemsnittene varierer klart over de forskellige brancher, men spredningen gør det i de fleste tilfælde umuligt at fastslå om gennemsnittene er forskellig fra branche til branche. En økonomisk typifisering af selskaberne kan derfor ikke gøres ud fra branchebetegnelsen.
Infouddragning
– de individuelle nøgletal
Med henblik på at afgøre om der var visse koncentrationer af nøgletallene gennemførtes først en frekvensanalyse. Selv ved forholdvis snævre intervaller var der ikke tydelige ujævnheder i fordelingerne for de enkelte nøgletal, som kunne indikere visse koncentrationer i observationsmaterialet. Derfor sorteredes nøgletallene efter størrelse og frekvensfordelingen af førstedifferencerne viste en tydelig overvægt i de nederste og i de øverste intervaller. Overhyppigheden i de øverste intervaller kan henføres til at nøgletallene er ret udpræget højreskæve fordelt, men overvægten i de nederste intervaller må skyldes at mange observationer ligger meget tæt på hinanden. Dette bekræftedes ved en beregning af en glidende standardafvigelse over 20 og 30 obeservationer på de størrelses-sorterede nøgletalsværdier. Udviklingen i den glidende standardafvigelse var som forventet nærmest bølgeagtig med markante forskelle mellem bund- og topværdier – også når der sås bort fra 80 største vædier dvs de værdier der ligger ude i fordelingens højre hale. Altså en klar indikation af at der var tydelige koncentrationer i datamaterialet og dermed også en ledetråd for den fortsatte analyse.
Sammenholdtes disse koncentrationer med Børsens branchebetegnelse kunne 4 grupper identificeres umiddelbart: én gruppe med en overrepræsentation af selskaber i JERN og MASK-brancherne, en anden gruppe, hvor MEDI og KEMI-selskaberne var i overtal, en tredie gruppe domineret af ENGH-virksomheder og en fjerde gruppe bestående af SERV-virksomheder. Desuden var der en indikation på at BYGG og ENTR-selskaberne kunne skilles ud. De 2 største brancher ifølge Børsen – ITEL (Information og Telekommunikation) samt LEVN - kunne ikke spores. Da denne gruppering kun er baseret på koncentrationer af nøgletallene enkeltvis plus Børsens branchekode, er der tale om en meget simpel og grov opdeling.
Infouddragning
– kombination af nøgletal
Med henblik på at afdække betydningen af samspillet mellem de 3 nøgletal dannedes derfor 4 grupper med udgangspunkt i de nævnte brancher samt 4 grupper med udgangspunkt i BYGG/ENTR-, ITEL-, LEVN-, og DETH-selskaberne. Sidstnævnte 4 grupper medtoges dels af nysgerrighed, dels som kontrolgrupper. Hver gruppe bestod af 15 nærmeste naboer (k-NN, k –nearest neighbbors) – dvs. de 15 selskaber, der lå tættest sammen målt som summen af deres kvadrede afstand fra gennemsnittene målt i standardafvigelser[5] - altså

Min D beregnedes gennem en iterativ proces, som først beregner gennemsnittene for de 3 nøgletal for alle selskaber i gruppen samt hver enkelt selskabs akkumulerede afstand hvorefter selskabet med størst afstand findes. I andet gennemløb udgår dette selskab af beregningen. Det giver 3 nye gennemsnit og nye afstande for alle selskaber incl. det udeladte selskab og selskaberne med de 2 største afstande udpeges. I 3. gennemløb udelades disse 2 selskaber, nye gennemsnit og afstande beregnes, 3 fjerneste selskaber udpeges o.s.fr. Efter N-15 gennemløb vil de resterende 15 selskaber være de 15 selskaber, der ligger tættest på hinanden og det antages at de giver et tilfredsstillende estimat på gruppens tyngdepunkt..
Med udgangspunkt i disse 8 fixpunkter beregnedes vha. ovenstående udtryk alle øvrige selskabers afstande til hver enkelt gruppe. I første omgang bestemtes gruppetilhørsforholdet blot som den korteste afstand, men det resulterede i nogle ret diffuse og konturløse grupper. Eksempelvis sugede JERN-MASK-gruppen næsten 25% af alle selskaber til sig uden at det styrkede forventningen om, at der kunne identificeres en jernindustriel klynge i datamaterialet. Med henblik på at få en noget skarpere profil frem skærpedes kravet til de øvrige selskabers gruppetilhørsforhold til kun at omfatte de selskaber, som faldt indenfor det rum som gruppens 15 selskaber udspændte og det gav bonus. Selv med denne skærpede betingelse for et gruppetilhørsforhold næsten 4-dobledes JERN-MASK-gruppen, men der var nu et fælles kendetegn for stort set alle selskaber – nemlig at de var serieproducerende virksomheder. Gruppen omdøbtes derfor til PROD-gruppen.
En tilsvarende udvikling sås omkring KEMI-MEDI-gruppen – den opsugede bryggerierne, sukker- og oliefabrikker m.fl. Tydeligvis var KEMI-MEDI-gruppen samlingspunkt for Procesindustrien, PROC. ENGH-gruppen, der var den næststørste, omfattede selskaber fra alle brancher, som beskæftigede sig med import og engroshandel. Den mindste gruppe var SERV-virksomheder med ca. 5% tilslutning fra forskellige brancher. Måske bortset fra BYGG/ENTR-gruppen, der lidt klarere manifesterede sig som en entreprenørgruppe (ordreproducerende industri), var den ingen entydig samling omkring de sidste 4 grupper.
Infouddragning
– sammenvejning af nøgletal
Indtil nu har hele grupperingsarbejdet været baseret på en ligevægtning af de 3 nøgletal og at denne ensvægtning ville give et tilfredsstillende udgangspunkt for en beregning, der kunne klassificere de enkelte virksomheder i forskellige typer svarende til lærebøgernes opdeling. Som nævnt ovenfor var dette ikke umiddelbart tilfældet. Den anvendte grupperingsteknik, k-NN, bevirker, at det rum, som de 3 variable udspænder stort set bliver helt symetrisk målt i standardafvigelser, men er det nu også tilfældet i virkelighedens verden? Kunne man ikke forestille sig, at en høj omsætning pr. medarbejder skyldtes en stor investering pr. medarbejder eller at en lav omsætningshastighed for aktiverne kompenseredes af en høj omsætning pr. medarbejder? Hvis det er tilfældet vil den ovenfor anvendte symmetriske gruppedannelse uheldigvis lige netop skære sådanne virksomheder væk.
Et andet problematisk forhold er, om det centrum, som de 15 oprindelige selskaber i grupperne konstituerer, nu også er det sande centrum for de pågældende grupper? Hvis det beregnede centrum afviger systematisk fra det sande centrum, vil det medføre en fejlagtig afskæring af selskaber i koncentreringsberegningerne. Det ville derfor være ønskeligt om det rum, som de forskellige grupper falder i, kunne afgrænses mere frit i forhold til det oprindelige centrum og i forhold til de mere individuelle forskelle i nøgletallene såvel indenfor gruppen som i forhold til de øvrige grupper.
En lille allegori: Da der – tilfældigvis - er tale om 3 nøgletal kan hver gruppe opfattes som 3-dimensionale legemer med ukendte men sandsynligvis forskellige former. Én gruppe kunne være appelsinformet, en anden pæreformet, en tredje bananformet, en fjerde på størrelse med en vindrue og en femte på størrelse med en mellon. Da alle ’frugterne’ ligger i den samme frugtskål er det ønskeligt at der kunne lægge nogle ’snit’ ind, der maksimerer sandsynligheden for at man får ’appelsin’ for sig og ’banan’ for sig o.s.fr. Med nedennævnte model skæres nogle fuldstændig lige snit ind i ’frugtkurven’ og med de forskellige former in mente vil det helt sikkert meføre at der ’hugges en hæl og klippes en tå’, men at kernen forbliver intakt. Det er muligt at en ’krumkniv’ ville være et bedre redskab, men hvilken krumning skulle så vælges?
Diskriminantanalysen er en velegnet teknik til klassifikation når inputvariablerne er kontinuerte. Metoden beregner med hvilken vægt de enkelte variable skal indgå for at opnå den bedst mulige grænsedragning mellem 2 eller flere grupper. Antallet af variable og observationer er i nærværende tilfælde dog for lille til simultan opdeling i mere end 2 grupper og derfor anvendtes en additiv model til at bestemme den bedste afskæringsværdi mellem grupperne 2 og 2, altså
d = b0 + b1x1
+ b2x2 + b3x3 + e
hvor x1,
x2 og x3 er de 3
nøgletal, der indgår i analysen og hvor d er en diskret variabel, der antager
værdien 0 når selskabet tilhører gruppe
1 og værdien 1 når selskabet tilhører gruppe 2. Ved hjælp af mindste kvadraters
metode – multipel lineær regression – kan vægtene b bestemmes. Da d kun antager
værdierne 0 eller 1 vil algoritmen beregne vægte, b1, b2
og b3 , som resulterer i at selska-ber i gruppe 1 får værdier, der
spreder sig rundt omkring 0 og selskaber i gruppe 2 får værdier, der spreder
sig rundt omkring 1 med en risiko for en vis overlapning. Der må derfor også
fastlægges en afskæringsværdi som deler intervallet fra 0 til 1 i to, således at
når d < afskæringsværdien tilhører selskabet gruppe 1 og d >
afskæringsværdien er det et selskab tilhørende gruppe 2 Hvis
residual-leddet, e, er N(0,1) fordelt
kan den bedste afskæringsværdi bestemmes som den gennemsnitlige ![]() 1 for selskaberne
i gruppe 1 og den gennemsnitlige
1 for selskaberne
i gruppe 1 og den gennemsnitlige ![]() 2 for
selskaberne i gruppe2 vægtet med antallet af observationer i de 2 grupper, dvs
2 for
selskaberne i gruppe2 vægtet med antallet af observationer i de 2 grupper, dvs
![]()
hvor n1 og n2 er antal selskaber i hver af de 2 grupper. Hvis standardafvigelsen på residualleddet for de grupper er forskellige opnås dog en mere præcis afskæring ved også at vægte gennemsnittene d1 og d2 med standardafvigelserne:
![]()
hvor se1 og se2 er standardafvigelsen på restleddet. Sidstnævnte afskæring gav i almindelighed det bedste resultat – dvs færrest fejlklassificerede selskaber.
Som nævnt var det kun muligt at bestemme vægtene og afskæringsværdier for 2 grupper ad gangen og med 8 forskellige grupper vil det resultere i 28 beregninger. Da det var noget uklart hvordan de enkelte grupper lå i forhold til hinanden og da hver gruppe skulle afgrænses mod 7 andre og helst så klart som muligt og da den samme stikprøve skulle anvendes i alle 7 beregninger valgtes nogle ret ’snævre’ stikprøver ud af de ovenfor nævnte grupper – nemlig de 50 nærmeste naboer i PROD, 40 nærmeste naboer i ENGH og de 20 nærmeste naboer i de øvrige grupper bortset fra SERV som kun omfattede 18 selskaber. Valget af nærmeste naboer sikrer at afstanden mellem de enkelte grupper er størst mulig og dermed også størst sandsynlighed for at grupperne kan adskilles, men omvendt betyder det også at stikprøvens variabilitet er ret begrænset og at dens repræsentavitet for gruppen som helhed er mindre end sædvanlig. Konsekvensen vil være at klassifikationsevnen i stikprøven vil overestimere den faktiske opdelingsformåen i hele populationen.
For PROD – ENGH kan diskriminantfunktionen estimeres til:
d = -1,44 +
0,72*AOH – 0,27*oms/medarb + 1,11*inv/medarb.
med en korrelationskoefficient på 0,89 og med vægte, der alle er signifikante med p-værdier på under 0,05. Rent statistisk er det udtryk for at der er en meget klar forskel mellem de 2 grupper PROD – ENGH. Disse statistiske mål er dog af begrænset interesse, idet de ikke umiddelbart kan relateres til opgaven: at afgrænse grupperne fra hinanden.
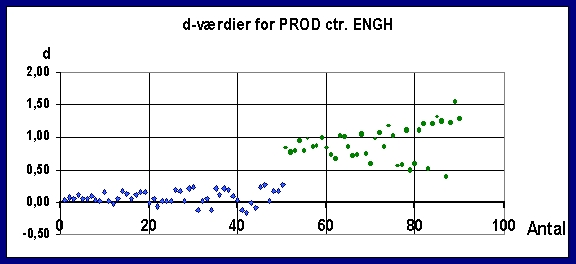
Scatterdiagrammet
figur 1 viser de beregnede d-værdier for de ialt 90 selskaber i de 2 grupper.
Det ses at produktionsvirksomhedernes d-værdier fordeler sig rundt 0 og
engroshandelens omkring 1. Gennemsnittene kan beregnes til ![]() = 0,08 og
= 0,08 og ![]() = 0,90, altså en
afstand på 0,82. Da standardfejlen på residualleddet e, S(e), kan beregnes til
0,208 kan den relative afstand beregnes til 3,98. Afstanden målt i
standardafvigelser er det bedste generelle udtryk for funktionens
diskriminations-evne, idet det er sammenligneligt over alle beregninger. Den
optimale afskæringsværdi kan beregnes til 0,367 og da min(dENGH) =
0,386 og max(dPROD) = 0,284 ses det at den giver en perfekt
klassifikation af de 90 selskaber. Denne fuldstændige tvedeling er dog et
resultat af stikprøveudvælgelsen og er opnået på bekostning af modellens
generalitet, idet en afstand på 3,98 standardafvigelser i en normalfordelt
population ville resultere i at ca. 4 % af observationerne – svarende til ca. 4
selskaber - ville blive fejlklassificeret.
= 0,90, altså en
afstand på 0,82. Da standardfejlen på residualleddet e, S(e), kan beregnes til
0,208 kan den relative afstand beregnes til 3,98. Afstanden målt i
standardafvigelser er det bedste generelle udtryk for funktionens
diskriminations-evne, idet det er sammenligneligt over alle beregninger. Den
optimale afskæringsværdi kan beregnes til 0,367 og da min(dENGH) =
0,386 og max(dPROD) = 0,284 ses det at den giver en perfekt
klassifikation af de 90 selskaber. Denne fuldstændige tvedeling er dog et
resultat af stikprøveudvælgelsen og er opnået på bekostning af modellens
generalitet, idet en afstand på 3,98 standardafvigelser i en normalfordelt
population ville resultere i at ca. 4 % af observationerne – svarende til ca. 4
selskaber - ville blive fejlklassificeret.
Figur 1. Aktuelle diskriminantværdier for PROD - ENGH
I tabel 2 er vist regressionskoefficienter og afstande målt i standardafvigelser for alle 28 diskriminantfunktioner. I en normalfordelt population vil en afstand på 2 standardafvigelser resultere i at ca. 1 ud af 3 observationer vil blive fejlklassificeret, men den snævre stikprøveudvælgelse resulterer i en væsentligt bedre diskrimanation mellem stikprøverne.
Bortset fra
BYGG-gruppen er
produktionsvirksomhederne med de 7 diskriminantfunktioner relativt vel
defineret vis-a-vis de øvrige 6 grupper, idet afstandene til de øvrige grupper
ligger på 2,13 til 4,09 standardafvigelser. Den store lighed mellem
nøgletallene for BYGG og PROD skal antagelig søges i det forhold at flere
BYGG-virksomheder i højere grad er produktionsvirksomheder end de er entreprenørvirksomheder
– dvs ordreproducerende. Som forventet er der en meget klar forskel mellem
nøgletallene for grupperne PROD, ENGH, PROC og SERV, medens afgrænsningen de 4
øvrige grupper er ret begrænset og mellem de sidste 4 grupper indbyrdes ikke er
nogen konstaterbar forskel.
Tabel 2:
Regressionskoeficienter og afstande for de 8 grupper
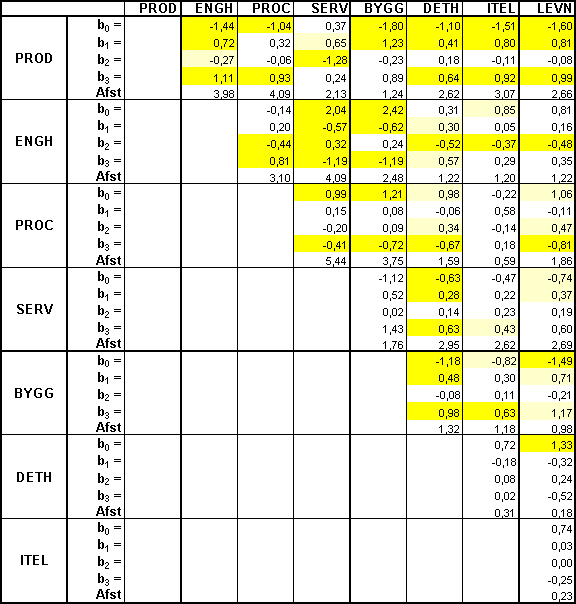
Note: farverne angiver
signifikansniveau: skarp gul p < 0,01 og lys gul p< 0.05
Gruppering
af selskaberne
Diskriminantfunktionernes effektivitet er testet på alle 433 selskaber. Principielt kan de opstillede diskriminantfunktioner kun tvedele observationsmaterialet i 2 klasser – enten gruppe 1 eller gruppe 2 afhængig af om d er mindre end eller større end den beregnede afskæringsværdi. Resultatet var imidlertid at en række selskabers d-værdier var meget store eller meget små – dvs. det måtte antages at disse selskaber faldt helt udenfor det rum de 7 diskriminantfunktioner afgrænser rundt omkring hver gruppe. Derfor opdeltes udfaldsrummet for d i 4 klasser, nemlig extreme-u, gruppe 1, gruppe 2 og extreme-0. jfr. fig 2.
Figur 2: d´s udfaldsrum
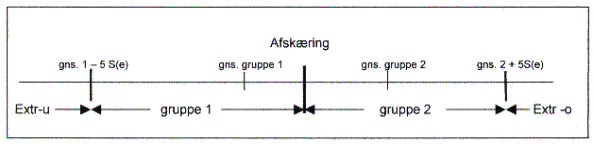
Under og
overgrænsen for extremværdierne blev fastsat ret arbitrært til gennemsnit
gruppe 1 minus 5 gange standardfejlen på estimatet og tilsvarende for
overgrænsen. I en normalfordelt population ville 3 S(e) have været
tilstrækkelig, men på baggrund af at de snævre stikprøver, der dannede grundlag
for estimeringen af diskriminantfunktionerne, må det antages at den beregnede
S(e) underestimerer den sande fejl på e.
 For at afgøre om et
selskab tilhørte eksempelvis produktionsgruppen må der gennemføres 7 tests
vis-a-vis alle de øvrige grupper. Som følge heraf kunne et selskab maximalt 7
gange blive klassificeret i én og samme gruppe 1. På baggrund af testene
opstilledes en såkaldt konfussionsmatrice, der viser hvor mange gange det
enkelte selskab blev klassificeret som gruppe 1 selskab, som gruppe 2 selskab
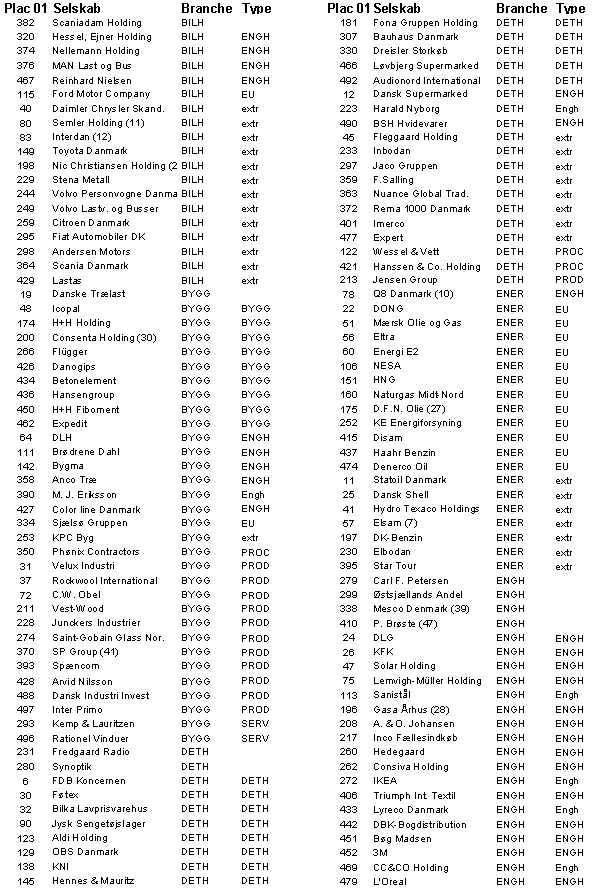
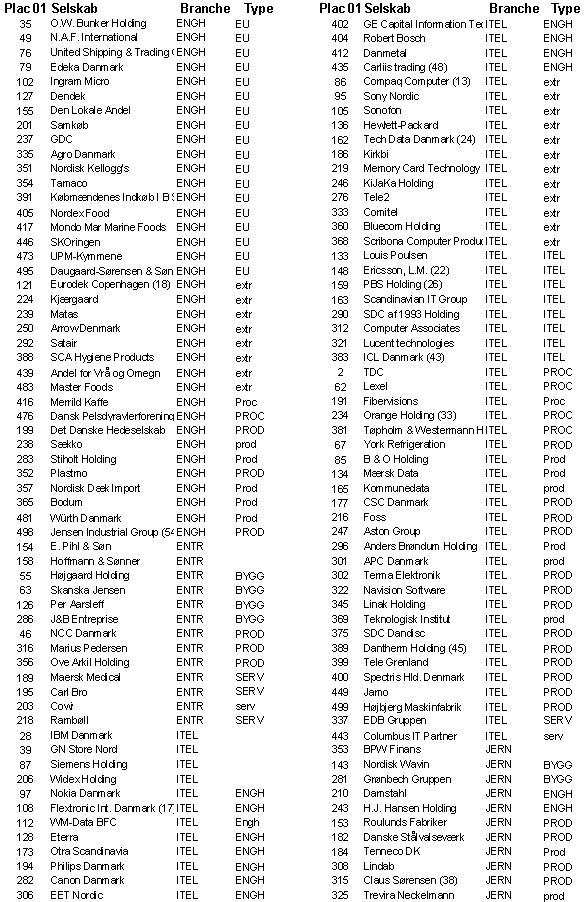
o.s.fr. Resultatet af denne klassifikation er vist i bilag A. Her angiver en
gruppebetegnelse med store bogstaver at selskabet i 7 ud af 7 tilfælde er
klassificeret i den pågældende gruppe, stort begyndelsesbogstav: at selskabet i
6 ud af 7 gange er klassificeret i gruppen og 4 små bogstaver: at selskabet i 5
ud af 7 tilfælde er klassificeret i gruppen.
For at afgøre om et
selskab tilhørte eksempelvis produktionsgruppen må der gennemføres 7 tests
vis-a-vis alle de øvrige grupper. Som følge heraf kunne et selskab maximalt 7
gange blive klassificeret i én og samme gruppe 1. På baggrund af testene
opstilledes en såkaldt konfussionsmatrice, der viser hvor mange gange det
enkelte selskab blev klassificeret som gruppe 1 selskab, som gruppe 2 selskab
o.s.fr. Resultatet af denne klassifikation er vist i bilag A. Her angiver en
gruppebetegnelse med store bogstaver at selskabet i 7 ud af 7 tilfælde er
klassificeret i den pågældende gruppe, stort begyndelsesbogstav: at selskabet i
6 ud af 7 gange er klassificeret i gruppen og 4 små bogstaver: at selskabet i 5
ud af 7 tilfælde er klassificeret i gruppen.
Af de i alt 433
selskaber blev de 133 selskaber klassificeret som produktionsselskaber – i 92
tilfælde entydigt, medens de resterende 41 selskaber havde 1 eller 2 gruppe 2
klassifikationer. 78 selskaber blev i fem eller flere tilfælde klassificeret
som extreme, medens 30 virksomheder blev klassificeret i mindst 4 forskellige
grupper, hvorfor deres gruppetilhørsforhold ikke kunne bestemmes. Som forventet
er der ingen økonomisk fællsenævner for Informations og Telekommunikationsgruppen
(ITEL) – kun 8 ud af 62 selskaber kan med en vis velvilje siges at udvise nogle
meget beskedne økonomiske fællestræk. Overraskende nok fandtes en økonomisk set
ret homogen gruppe i levnedsmiddelgruppen centreret omkring slagterierne / landbrugsforarbejdende
virksomheder. En umiddelbar hypotese ville være, at det var en
’andelsselskabsfaktor’, der her var trukket ud af dataene, men da flere
selskaber aldrig har været andelsselskaber, må homogeniteten antagelig være
forårsaget af det ensartede virkefeldt og konkurrenceforholdene.
DETH-selskaberne – i alt 13 er klassificeret som sådan – er på trods af
klassifikationen økonomisk set meget forskellige.
I alt 49
virksomheder er blevet klassificeret som procesvirksomheder. En nøjere
gennemgang af PROC-selskaberne viser imidlertid, at nok afgrænser de 7
diskriminantfunktioner procesvirksomhederne, men det fælles kendetegn for alle
virksomheder i denne gruppe er kapitalintensive virksomheder. Til
servicegruppen er henregnet i alt 19 selskaber, men heraf hører kun syv til den
SERV-branche, som Børsen har udarbejdet – 12 selskaber er altså henregnet til
andre brancher af Børsen.
Ved en gennemgang
af bilag A vil det ses at den statistiske typifisering af de 433 virksomheder ikke
er fejlfri, men det er egentlig ikke så væsentlig i denne forbindelse. Det
væsentlige er at dataene – den kategoriale branchekode og de kontinuerte:
omsætning, balancesum og antal ansatte - i sig selv indeholder en ikke-synlig
information, som gør det muligt, at foretage en sådan ret entydig
klassifikation samt naturligvis implikationen af denne klassifikation.
Resultatet
I figur 3 næste
side er vist det egentlige mål med denne data mining – nemlig hvordan kan den
typiske produktionsvirksomhed, den typiske servicevirksomhed osv.
karakteriseres ud fra nogle centrale økonomiske data. For hver virksomhedstype
er beregnet gennemsnittet af aktivernes omsætningshastighed, omsætning pr.
ansat og investering pr ansat samt et 95% konfidensinterval. I øverste tredjedel
er de forskellige virksomhedstyper sorteret efter aktivernes
omsætningshastighed, i midterste tredjedel efter omsætning pr. ansat og i
nederst efter investering pr. medarbejder.
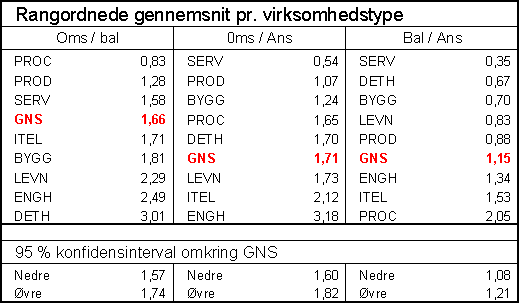
Det ses, at i
procesindustrien omsættes aktiverne uhyre langsomt – ca. 0,8 gange pr år. Det
meget snævre konfidensinterval indikerer, at det er et gennemgående og meget
karakteristisk vilkår for hele industrien. Aktivernes omsætningshastighed er
også særdeles entydig i den serieproducerende industri, men hastigheden er 50%
højere end i procesindustrien – mao. procesindustrien skal investere 1,25 kr
for at få 1 krones omsætning medens den mere traditionelle industri klarer det
for ca. 0,80 kr! Det har naturligvis en meget klar konsekvens for styringen af
den anden betydelig ressource – nemlig medarbejderne. Medarbejdereffektiviteten
– målt som omsætning pr medarbejder – er da stort set også omvendt proportional
med aktivernes omsætningshastighed – i procesindustrien er omsætningen ca. 1,7
mio kr pr medarbejder medens serieindustrien ligger så lavt som 1,1 mio. kr.
Den meget store forskel i investeringsomfanget i de to industrier – i
gennemsnit 2,1 mio. kr. pr medarbejder i procesindustrien mod beskedne 0,8 mio.
kr. i serieindustrien – kompenseres derimod i udpræget grad gennem den opnåede
bruttoavance på de solgte produkter.
Opgjort på denne
måde kommer servicevirksomhederne noget uventet på 3. pladsen som den mest
kapitalintensive virksomhed med ca. 0,60 kr investering pr. omsætningskrone.
Der er en noget større variabilitet i serviceselskaberne mht. aktivernes
omsætningshastighed, idet konfidensintervallet er flere gange større end i den
serieproducerende industri – 0,38 mod 0.12. Da der ingen overlapning er mellem
de 2 konfidensintervaller, er det ensbetydende med, at den gennemsnitlige AOH
statistisk set er klart større i serviceindustrien end i serieproduktionen,
jfr. at b1 = 0,65 i tabel 2 er markeret let skraveret, hvilket
indikerer, at der på 5 %-niveauet er en signifikant forskel mellem
omsætningshastighederne i de to virksomhedstyper. Den kunstige gruppe ITEL kan overhovedet ikke karakteriseres ud
fra de givne nøgletal. Derimod er BYGG / ordreproducerende industri ret
veldefineret ved de givne nøgletal, idet konfidensintervallet størrelsesmæssigt
svarer til service og engroshandel. Det ses at der er en vis overlapning af
konfidensintervallerne for SERV og BYGG, hvorfor dette nøgletal ikke er særlig
pålidelig ved en skelnen mellem de 2 grupper.
Som tidligere nævnt
er der et vist statistisk belæg for en levnedsmiddelgruppe primært
identificeret ved en høj omsætning af aktiverne - 2,3 gange pr. år – hvilket
relativt klart adskiller den fra PROC, PROD, SERV og tildels BYGG medens den
stort set er sammenfaldende med ENGH – jfr. den næsten fuldstændige overlapning
af konfidensintervallerne. Dog er der en markant forskel mellem de to
virksomhedstyper når der ses på omsætning pr. ansat – 1,7 mio. kr. mod 3,2 mio.
kr. – og på investering pr. ansat – 0,9 mio. kr. mod 1,4 mio. kr. Rent statistisk
kan levnedsmiddelindustrien og detailhandelen ikke adskilles - der er næsten
100% overlapning af de 2 gruppers konfidensintervaller – men man er næppe i
tvivl når man står foran forretning eller et slagteri. Konfidensintervallet er
dog ret stort for alle 3 nøgletal, hvilket implicerer en noget mindre
homogenitet i gruppen.
Ikke uventet har
handelsvirksomhederne den hurtigste omsætning af aktiverne – 2,5 gange pr. år i
engros og 3 gange i detailhandelen. Men spredningen på detailhandelens
nøgletal gør det helt uanvendelig som
determinant for for denne gruppe.
Et (godt?) gæt på årsagen til
denne næsten absurde store spredning for iøvrigt ret ensartede virksomheder
kunne være, at nogle detailhandelsvirksomheder udfører visse engrosfunktioner
som f. eks. import og finansiering.
Omsætningen pr.
medarbejder – i gennemsnit 1,7 mio. kr. for de i alt 355 virksomheder, der er
fordelt på de 8 grupper – varierer fra godt en halv million pr.
servicemedarbejder til 3,2 mio kr i engroshandelsvirksomheder. Nogenlunde samme
spredning er der på investeringerne pr. ansat – fra 0,35 mio. kr i service til
2,1 mio. kr i procesindustrien. Flertallet af virksomheder ligger på omkring
trekvart mio. kr. pr. næse. At
engroshandelen ligger på næsten det dobbelte må antagelig henføres til den
betydelig finansiering af varehandelen, der ofte anføres som én af de
væsentligste opgaver for denne type virksomheder.
Anvendelsen
af resultatet
Og udbyttet af
denne data mining? Tjaaaaa......................og dog. Først og fremmest at dataene som sådan indeholder mere information end
deres absolutte værdier, og at det under anvendelsen af forskellige værktøjer
er muligt at uddrage en sådan ikke-synlig information, nemlig en gruppering /
typificering af erhvervsvirksomheder på en måde, der stemmer overens med den
traditionelle lærebogs systematisering af virksomhedsbegrebet. Den praktiske
anvendelighed - der er det andet krav til en vellykket DM - er i modsætning til
informations ekstraheringen specifik og konkret. Tallene kan anskues som en
form for samhørende type-karakteristiske normtal, der i den konkrete situation
- analyse / vurdering - giver en rettesnor for en klassificering af en
virksomhed ud fra en begrænset men
lettilgængelige datamængde.
Tabel 3: Virksomhedstypernes
karakteristiske nøgletalsværdier
|
Nøgletal Virksomhedtype |
Omsætning pr. balancekr. |
Omsætning pr. medarb, mio. kr. |
Investering pr medarb. mio. kr. |
|
Serieprod. industri |
1,28 |
1,07 |
0,88 |
|
Procesprod. industri |
0,83 |
1,65 |
2,05 |
|
Ordreprod. industri |
1,81 |
1,24 |
0,70 |
|
Levnedsmiddel industri |
2,29 |
1,73 |
0,83 |
|
Information & telekom. |
1,71 |
2,12 |
1,53 |
|
Engroshandel |
2,49 |
3,18 |
1,34 |
|
Detailhandel |
3,01 |
1,70 |
0,67 |
|
Service |
1,58 |
0,54 |
0,35 |
Betegnelsen ’rettesnor’ skal tages helt
bogstaveligt. Tallene prætenderer ikke at være absolutte eller entydige, men,
som nævnt under diskussionen af DM-begrebet,
blot et forbedret beslutningsgrundlag. Udover den usikkerhed, der kan
henføres til procedure- og beregningsmæssige forhold vil prisudviklingen
naturlivis relativt hurtigt gøre tallene invalide. Omsætning pr. heltidsansat
med-arbejder vil være mest følsom over for prisudviklingen på kort sigt, men på
blot mellemlangt sigt vil alle nøgletallene ændre sig som følge at
prisændringer. Ændringer i produktiviteten virksomhedstyperne imellem – der
sædvanligvis er noget langsommere – vil tillige medføre en forskydning af nøgletallene
indbyrdes.
Analysens resultater kan muligvis også
anvendes i et helt andet perspektiv. Det er måske mere forståeligt nu, at aktiemarkedet
har vendt tommelen nedad for ISS´s interesse for Sophus Berendsen. Sophus er i
bund og grund en produktionsvirksomhed og skal styres og ledes som sådan,
medens ISS´s ledelseserfaring stort set kun rækker til servicevirksomheder -
alle de produktions-virksomheder som ISS har ejet, har man afhændet som regel
som underskudsforretninger. Det er måske også mere forståeligt nu hvorfor
Magasin har så vanskeligt ved at få enderne til at hænge sammen. Med en
økonomisk struktur, der svarer til procesindustriens, men med en indtjening,
der svarer til detailhandelens, må der være en betydelig ubalance i systemet.
O
X O O X O O
X O
Bilag
Bilag A – klassificering af virksomherne
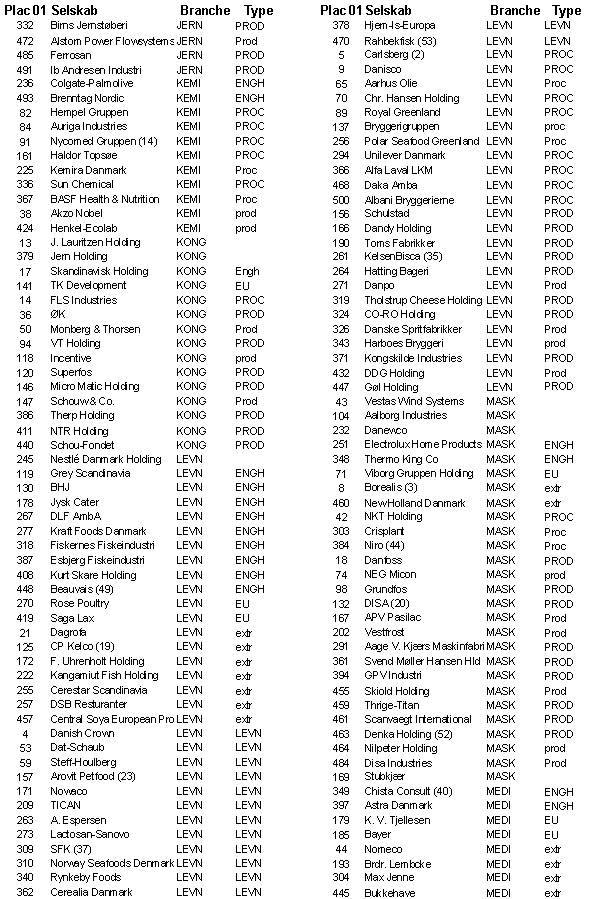
EU = ej undersøgt EU = ej undersøgte selskaber

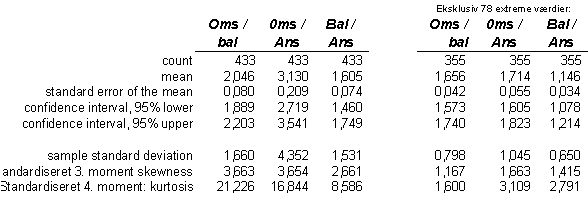
Bilag B –
gennesnitsværdier alle observationer
Bilag C – rangordnede
gennemsnit pr. virksomhedstype
Bilag D – normaliserede
afstande mellem virksomhedstyperne
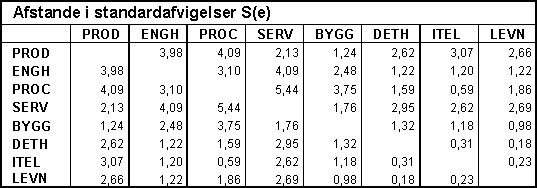
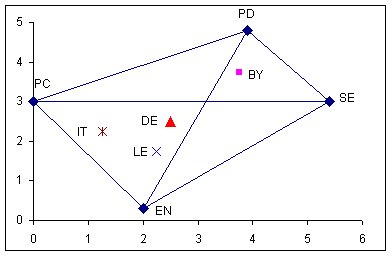
I en todimensionel
afbildning kan de 8 grupper placeres således i forhold til hinanden: